Starting from Go 1.7, SSA has been introduced into the Go toolchain
(This article is a translation of this Japanese blog post for which I got the friendly permission of the original author shinpeinktさん. Many thanks!)
Introduction
Go 1.7 will soon be released (note by the translator: since the original blog post has been published, Go 1.7 has been released already). One of the most prominent changes is that the SSA-IR (Intermediate Representation) has been introduced into the Golang compiler.
“We will get SSA, but what is it?” is what I was asked in an Izakaya and what prompted me to write this blog post. My knowledge in the matter wasn’t enough to complete the whole picture so I looked things up and condensed what I learned into this text.
This blog post is not a general treatment of SSA but follows the topic in relation to Go (the code of the Go compiler can be found at cmd/compile/internal/gc). For a more general view, I would like to refer the reader to the reference section. After looking into the topic, I thought that what you need to know about the added SSA is not necessarily the answer to the question “what is SSA?” in a general sense but more an answer to the question of “how has Go changed now that SSA has been introduced?”.
What is SSA?
SSA stands for Static Single Assignment. This is a code form that guarantees that each variable gets assigned a value only once. This code form is said to make optimisation easier and there are compiler optimisations that depend on SSA being used, like GVN for example. Before we have a look at how SSA got introduced, we will concern ourselves with the optimisation of the current version of Go (Go 1.6).
Why is optimisation necessary?
SSA is used for optimisation purposes. To understand why that is we have to look at the optimisation a compiler is doing. First we look at how a compiler without any optimisations produces machine code (readers that already know about this can skip directly to the “What is the issue with this process in Go 1.6?” section.) To put it simply, a compiler stupidly translate a program line-by-line into machine code.
Let’s say we have the following code.
a := 3 // (a)
b := 4 // (b)
c := a + b // (c)
If we compile this without applying any optimisations, it will look like this.
MOVQ $0x3 0x10(SP) // (1) <-- (a)
MOVQ $0x4 0x8(SP) // (2) <-- (b)
MOVQ 0x10(SP) BX // (3) <-- (c)
MOVQ 0x8(SP) R8 // (4) <-- (c)
ADDQ R8 BX // (5) <-- (c)
MOVQ BX 0(SP) // (6) <-- (c)
The comments show how both representations are related. (a)–(c) are roughly translated to the corresponding lines (1)–(6). When we assign values to variables like in (a) and (b), we transfer their values to their addresses (which are in the stack regions used for variables). Then, in (c), we do the calculation and in (3) and (4) we read the values that we stored in the variables before into the registers BX and R8. In (5) those values are added together and in (6) the result of the addition is again written to the stack area reserved for variables.
How can we execute these machine code lines more efficiently? In the lines (1)–(4) above we store the values that we need for the calculation into variables only to read them again into registers immediately after which is a waste of time. What we should do instead is to read the values that we need for the calculation into the registers directly from the beginning. With non-optimized code like this the relation between the underlying source code and the generated machine code is very obvious. This is an indication that the source code has been simply translated line-by-line by the compiler without applying any optimisations.
The optimisation in Go 1.6
The directly translated code was doing things inefficiently. The
optimisation step takes this inefficient code and automatically transforms
it into a more desirable form. In versions before Go 1.6 there were two
compilation steps in the compiler that can be countd as optimisations
(if we only look at the optimisations that could be triggered by
using the -N flag). They were performed by the nilopt
and regopt functions. Code like the above would be optimised by regopt
so let’s talk about that function (its code can be found in
reg.go).
What the function does is generally called “register allocation.” Operations on a CPU, which means almost all operations a computer does, are being performed by reading values into registers and then doing calculations with them. Because the number of registers in a CPU is limited, it poses the problem of how to use them in the most effective way. What is usually being done is to mark the registers that are in use in the generated instructions and try to use the unused registers in the instructions that follow. If the compiler proceeds with this strategy, the instructions that are generated will look like this.
MOVQ $0x3, CX
MOVQ $0x4, AX
MOVQ CX, BX
MOVQ AX, R8
ADDQ R8, BX
MOVQ BX, AX
The spilling of values into variables on the stack that was
performed in (1) and (2) above has disappeared and we can see
that instead we are performing direct writes into registers
(I forgot to mention that AX and BX are the
name of the registers. An overview of their names can be found
here).
Still, the efficiency is not there yet. What we want to happen is that the
values are written to the registers R8 and BX directly since
these are the ones that the ADD instruction is using. After this step, an
operation called peephole optimisation takes place. This is known
as a local optimisation and works about like this: we look at the code,
see that there is a place that is obviously lacking in efficiency and
apply an ad hoc optimisation. If we use this peephole optimisation
at this point, we arrive at the code below.
MOVQ $0x3, BX
MOVQ $0x4, AX
ADDQ AX, BX
If we have come this far, we have succeeded in generating machine code that is reasonable and it would be time to measure how big the improvement turns out to be in practice.
What is the issue with this process in Go 1.6?
It is less of an issue and more the case that the optimisation process in Go 1.6 has parts that are not well developed. One could go as far to say that there has not been invested a lot of time into it yet. The proposal document for SSA begins with the following (paraphrased) paragraph “It is a well-known fact that with Go 1.5 the Go language has been rewritten completely in Go itself. If we now change the Syntax-tree-based IR of Go into a modern, SSA-based one (which would have been difficult to implement at the time of Go 1.4) there is a wide array of optimisations available to us” (analogous translation). In other words, what led to the introduction of SSA is less of a “I obviously want to do this optimisation!"-sentiment and more of subdued motivation like “if we first change this to SSA it looks like we could introduce quite a lot of optimisations.”
What has changed with the introduction of SSA?
SSA has been introduced with the assumption that it will make further code generation optimisations easier. So which optimisations are now included in Go 1.7? I tried to list them and it turns out that there is quite a few of them included now. For each one, the list mentions the function name so the optimisation step that is being performed in it can be checked by looking at the definitions of these functions.
var passes = [...]pass{
// TODO: combine phielim and copyelim into a single pass?
{name: "early phielim", fn: phielim},
{name: "early copyelim", fn: copyelim},
{name: "early deadcode", fn: deadcode}, // remove generated dead code to avoid doing pointless work during opt
{name: "short circuit", fn: shortcircuit},
{name: "decompose user", fn: decomposeUser, required: true},
{name: "opt", fn: opt, required: true}, // TODO: split required rules and optimizing rules
{name: "zero arg cse", fn: zcse, required: true}, // required to merge OpSB values
{name: "opt deadcode", fn: deadcode, required: true}, // remove any blocks orphaned during opt
{name: "generic domtree", fn: domTree},
{name: "generic cse", fn: cse},
{name: "phiopt", fn: phiopt},
{name: "nilcheckelim", fn: nilcheckelim},
{name: "prove", fn: prove},
{name: "loopbce", fn: loopbce},
{name: "decompose builtin", fn: decomposeBuiltIn, required: true},
{name: "dec", fn: dec, required: true},
{name: "late opt", fn: opt, required: true}, // TODO: split required rules and optimizing rules
{name: "generic deadcode", fn: deadcode},
{name: "check bce", fn: checkbce},
{name: "fuse", fn: fuse},
{name: "dse", fn: dse},
{name: "tighten", fn: tighten}, // move values closer to their uses
{name: "lower", fn: lower, required: true},
{name: "lowered cse", fn: cse},
{name: "lowered deadcode", fn: deadcode, required: true},
{name: "checkLower", fn: checkLower, required: true},
{name: "late phielim", fn: phielim},
{name: "late copyelim", fn: copyelim},
{name: "phi tighten", fn: phiTighten},
{name: "late deadcode", fn: deadcode},
{name: "critical", fn: critical, required: true}, // remove critical edges
{name: "likelyadjust", fn: likelyadjust},
{name: "layout", fn: layout, required: true}, // schedule blocks
{name: "schedule", fn: schedule, required: true}, // schedule values
{name: "flagalloc", fn: flagalloc, required: true}, // allocate flags register
{name: "regalloc", fn: regalloc, required: true}, // allocate int & float registers + stack slots
{name: "trim", fn: trim}, // remove empty blocks
}
The code in SSA form goes through all those optimisation stages. Then, after each of those processing steps has been applied successfully to the code, the machine code will be generated from it.
The person implementing these efforts has left a nice debugging functionality in for us. Try to compile your code with
GOSSAFUNC=main go build
where GOSSAFUNC should contain the name of the function you want to
debug. In addition to the compiled binary you should get an HTML file
called ssa.html. This file shows the SSA form at each stage
of the processing pipeline. Below you can see the result of the
compilation of the first program. In the early deadcode stage a
whole function is eliminated. This was a wrapper function I added for test
purposes and it was eliminated because the function ended with a _ = c statement.

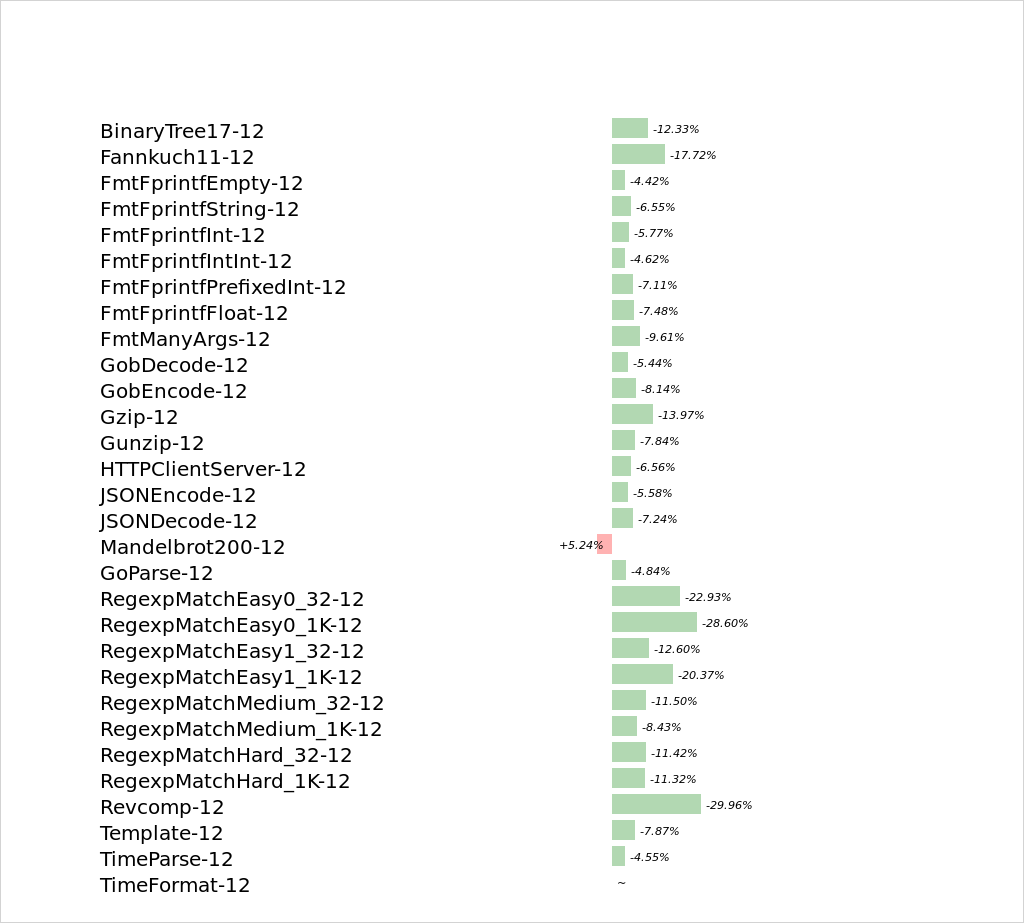
At the end of the optimisation step, almost all benchmarks showed a 5~35%
speedup and the binary size has gotten about 20% smaller. This is thanks
to the elimination of superfluous code. On the other hand, the compile
time (only the code generation step) has increased by about 10%. I only
learned through what other people mentioned, that the go build
time improved in spite of that because the linker stage has gotten a lot
faster.
Conclusion
Yesterday at the Go Release party Tokyo I chatted with people about SSA. I wanted to talk about what SSA actually is but because we barely touched upon how SSA in Go works I decided to write this blog post. Also, later than I would have hoped, let me now answer the questions that we did not have time to address in the Question & Answer session.
Questions & Answers
Q1. There are benchmarks that have gotten slower with Go 1.7, what is the reason for that?
A1. These benchmark results can be seen here. It’s the Mandelbrot benchmark that has gotten slower. The answer can be found in the mailing list. The code of the Mandelbrot benchmark contains nested loops. It looks like the register allocation done through to the peephole optimisation is weaker in this case when using the SSA IR. The people on the mailing list assume that they will be able to improve on that in the future.
{kind=link}
Q2. Is there code of which you can say that it automatically gets faster when you write it in a certain way?
A2. As shown in the Mandelbrot benchmark above, SSA seems to be somewhat weak at doing loop optimisations. This means that complex loops have been optimized better in Go 1.6 and before. One can thus assume that if you have code with a lot of nested loops, doing the optimisation by hand will result in better speed gains.
References:
- レジスタ割り付け
- コンパイラの構成と最適化
- Go 1.7 toolchain improvements, Dave Cheney